大數(shù)據(jù)處理技術(shù) 從數(shù)據(jù)洪流中提煉價(jià)值的核心技藝

在當(dāng)今信息爆炸的時(shí)代,大數(shù)據(jù)已成為驅(qū)動社會進(jìn)步和商業(yè)創(chuàng)新的關(guān)鍵燃料。而大數(shù)據(jù)處理技術(shù),正是將原始、海量、異構(gòu)的數(shù)據(jù)轉(zhuǎn)化為有價(jià)值信息和洞見的系統(tǒng)化方法與工具集。它并非單一學(xué)科,而是一個(gè)融合了計(jì)算機(jī)科學(xué)、統(tǒng)計(jì)學(xué)、數(shù)學(xué)和應(yīng)用領(lǐng)域知識的綜合性技術(shù)體系。要掌握這門核心技術(shù),究竟需要學(xué)習(xí)什么呢?其核心正是圍繞 “數(shù)據(jù)處理” 這一生命線展開的多個(gè)層面。
一、 基礎(chǔ)理論與架構(gòu)認(rèn)知
這是學(xué)習(xí)的起點(diǎn),旨在構(gòu)建對大數(shù)據(jù)生態(tài)的宏觀理解。
- 大數(shù)據(jù)核心特征(4V+):深刻理解Volume(海量)、Velocity(高速)、Variety(多樣)、Value(低價(jià)值密度)以及Veracity(真實(shí)性)等特征,是設(shè)計(jì)所有處理方案的前提。
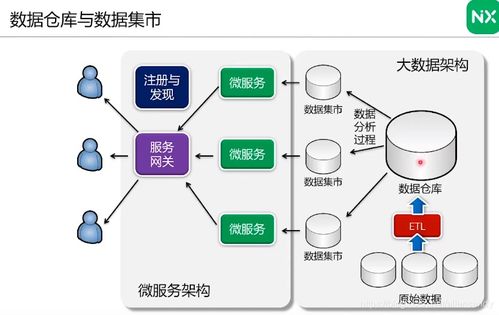
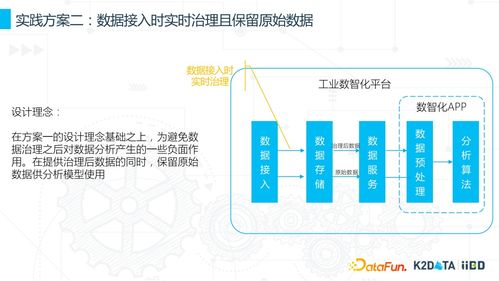
- 分布式系統(tǒng)原理:大數(shù)據(jù)處理離不開分布式計(jì)算。需要學(xué)習(xí)分布式文件系統(tǒng)(如HDFS的設(shè)計(jì)思想)、集群管理、容錯(cuò)機(jī)制、以及計(jì)算如何向數(shù)據(jù)遷移而非相反的核心哲學(xué)。
- 主流處理框架與范式:掌握批處理(如Apache Hadoop MapReduce)、流處理(如Apache Flink, Apache Storm)、交互式查詢(如Apache Hive, Presto)以及圖處理等不同計(jì)算范式的適用場景與基本原理。
二、 數(shù)據(jù)處理的核心技能棧
這是技術(shù)學(xué)習(xí)的重中之重,貫穿數(shù)據(jù)從“原材料”到“成品”的全過程。
- 數(shù)據(jù)采集與集成:學(xué)習(xí)如何從數(shù)據(jù)庫、日志、傳感器、社交媒體等異構(gòu)源實(shí)時(shí)或批量采集數(shù)據(jù),涉及工具如Flume, Kafka, Sqoop等,并理解ETL(抽取、轉(zhuǎn)換、加載)流程。
- 數(shù)據(jù)存儲與管理:根據(jù)數(shù)據(jù)結(jié)構(gòu)和訪問模式,選擇合適的存儲方案,包括分布式文件系統(tǒng)、NoSQL數(shù)據(jù)庫(如HBase, Cassandra)、NewSQL數(shù)據(jù)庫、以及云存儲服務(wù)。
- 數(shù)據(jù)計(jì)算與加工:
- 批處理編程:深入掌握MapReduce編程模型,以及更上層的工具如Hive SQL、Spark SQL(使用DataFrame/Dataset API)進(jìn)行大規(guī)模數(shù)據(jù)集的分析。
- 流處理開發(fā):學(xué)習(xí)處理無界數(shù)據(jù)流,實(shí)現(xiàn)實(shí)時(shí)監(jiān)控、預(yù)警和分析,掌握窗口、狀態(tài)、時(shí)間語義等核心概念。
- 圖計(jì)算與機(jī)器學(xué)習(xí):了解基于大數(shù)據(jù)的圖算法和機(jī)器學(xué)習(xí)庫(如Spark MLlib)的應(yīng)用。
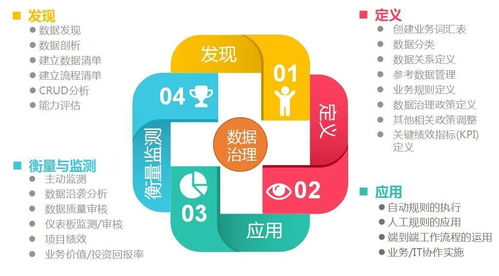
- 數(shù)據(jù)質(zhì)量與治理:確保數(shù)據(jù)的準(zhǔn)確性、一致性、完整性和時(shí)效性,學(xué)習(xí)數(shù)據(jù)清洗、去重、標(biāo)準(zhǔn)化、以及元數(shù)據(jù)管理、數(shù)據(jù)血緣追蹤等技術(shù)。
三、 編程語言與工具生態(tài)
1. 核心編程語言:Java/Scala 是Hadoop/Spark生態(tài)的基石,Python 憑借其豐富的數(shù)據(jù)科學(xué)生態(tài)(Pandas, NumPy, PySpark)成為數(shù)據(jù)分析和機(jī)器學(xué)習(xí)的首選,SQL 是進(jìn)行數(shù)據(jù)查詢和操作的通用語言,必須精通。
2. 生態(tài)工具鏈:熟悉以Apache Hadoop/YARN/Spark/Flink為核心的整個(gè)開源生態(tài),以及云平臺(如AWS EMR, Azure HDInsight)提供的托管服務(wù)。了解資源調(diào)度器(YARN, Kubernetes)、協(xié)調(diào)服務(wù)(ZooKeeper)等支撐性組件。
四、 進(jìn)階與跨界能力
1. 性能調(diào)優(yōu)與故障排查:學(xué)習(xí)如何對作業(yè)進(jìn)行性能優(yōu)化(如數(shù)據(jù)傾斜處理、內(nèi)存調(diào)優(yōu)、并行度調(diào)整),并具備集群和作業(yè)級別的故障診斷能力。
2. 數(shù)據(jù)倉庫與建模:理解維度建模(星型、雪花模型)、數(shù)據(jù)分層(ODS, DWD, DWS, ADS)、以及現(xiàn)代數(shù)據(jù)湖倉一體(Lakehouse)架構(gòu)。
3. 與數(shù)據(jù)分析和AI的銜接:明確大數(shù)據(jù)處理是為下游的數(shù)據(jù)分析、商業(yè)智能(BI)和人工智能(AI)模型訓(xùn)練提供高質(zhì)量、可用的數(shù)據(jù)平臺。需要了解基本的統(tǒng)計(jì)知識和機(jī)器學(xué)習(xí)流程。
4. 系統(tǒng)設(shè)計(jì)與架構(gòu)能力:能夠根據(jù)業(yè)務(wù)需求,設(shè)計(jì)高可用、可擴(kuò)展、成本效益合理的大數(shù)據(jù)處理平臺架構(gòu)。
而言,學(xué)習(xí)大數(shù)據(jù)處理技術(shù),是一場以 “數(shù)據(jù)處理” 為核心的深度旅程。它要求從業(yè)者既要有扎實(shí)的分布式系統(tǒng)理論基礎(chǔ),又要具備解決實(shí)際數(shù)據(jù)管道(從接入、存儲、計(jì)算到輸出)中各種工程問題的實(shí)戰(zhàn)能力,同時(shí)還需對不斷演進(jìn)的技術(shù)生態(tài)保持敏感。最終目標(biāo),是成為一名能夠駕馭數(shù)據(jù)洪流,為企業(yè)構(gòu)建高效、可靠數(shù)據(jù)價(jià)值生產(chǎn)線的工程師或架構(gòu)師。
如若轉(zhuǎn)載,請注明出處:http://www.6c2yg6qi.cn/product/47.html
更新時(shí)間:2026-01-14 11:29:49